
Introduction
Data mining, or Knowledge Discovery in Data (KDD), is finding patterns and other relevant information from huge databases. With the improvement of data warehousing technology and the proliferation of big data, the usage of data mining technology has increased dramatically in recent decades, supporting businesses in converting raw data into valuable information. Although this technology is continually growing to handle massive volumes of data, business executives still need to work on scalability and automation issues.
In this tutorial, you will learn about Data Summarization for Data Mining. You will also obtain a comprehensive grasp of the relevance of Data Mining, data summarizing, and the many techniques of implementing Data summarizing in Data Mining.
Read on to learn more about Data Summarization in Data Mining.
What is Data Mining?
Data mining is the process of extracting information from vast amounts of data. Essentially, it is a technique for extracting insights from data by mining. Data mining is the process of analyzing data to identify patterns, reveal connections, and expose anomalies that will allow you to take measures or steps to better your organization or cease specific activities that impede growth.

The data mining process begins with determining the business purpose to be achieved through extraction, followed by data collecting. The data is saved in a repository, where it is cleaned and organized to remove multiple/duplicate entries and add missing data. Data mining produces valuable information that companies may use to solve issues, anticipate trends, uncover new possibilities, detect anomalies, reveal relationships, and mitigate risks.
Data mining employs statistical and mathematical algorithms to reveal these patterns, allowing firms to use the information for market research, fraud detection, customer retention, production management, scientific investigation, and so on. Data mining may be used to make educated decisions in a variety of areas, including banking, healthcare, retail, manufacturing, and sports.
What is Data Summarization?
The word Data Summarization refers to the presenting of a summary/report of generated data in a clear and useful way. Summarization of the complete dataset is used to convey information about it. It is a meticulously crafted summary that will present trends and patterns from the dataset in a simpler format.

Data has become increasingly complicated, necessitating the need to summarize it to extract usable information. Data summarizing is very important in data mining because it may assist choose which statistical tests to employ based on the overall trends provided by the summary.
Summarizing Data in Data Mining
We simplify data so that patterns may be identified quickly. This introduces descriptive data summarization in data mining.
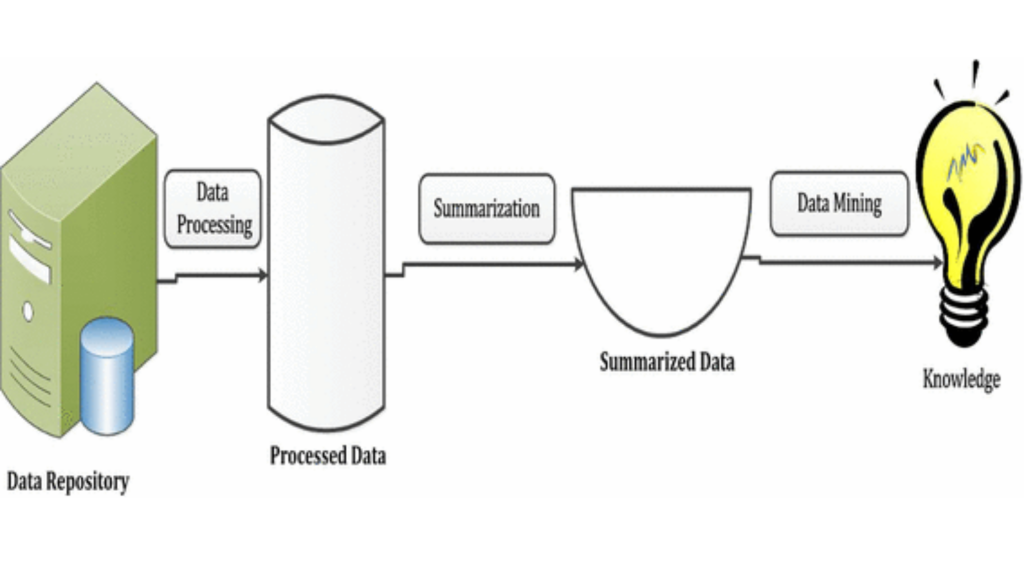
Data summarization is an important concept in data mining since it allows for a succinct explanation of a dataset to determine what appears regular or out of place. A correctly prepared summary of raw data would clearly illustrates many of the data’s trends and patterns. The phrase ‘data mining’ refers to exactly this process, which involves extracting relevant information from raw data. Data Summarization in Data Mining tries to provide extracted information and trends in a tabular or graphical style.
In general, data can be summarized numerically in the form of a table (tabular summary) or graphically in the form of a graph (data visualization).
There are several forms of data summarization in data mining:
- Data Visualization: Visualizations from a certain graph type, such as a histogram, time-series line graph, column/bar graph, and so on, can assist in identifying patterns quickly and graphically.
- Tabular Summarization: This approach quickly shows patterns like frequency distribution, cumulative frequency, etc.
Data Summarization may be implemented in three domains of Data Mining. They are as follows:
1.Data Summarization in Data Mining: Centrality
The Centrality principle describes the data’s center or middle value.
Several metrics may be used to illustrate centrality, the most frequent of which are average (also known as mean), median, and mode. They summarize the distribution of the sample data.
- Mean: This is used to calculate the numerical average of a collection of numbers.
- Mode: This is the most commonly repeated value in a dataset.
- Median: When values are listed in order, the median is the value that falls in the center of the list.
The most appropriate metric will be determined primarily by the geometry of the dataset.
2.Data Summarization in Data Mining: Dispersion
A sample’s dispersion relates to how evenly distributed the values are around the average (center). The spread of the distribution of data indicates the degree of variety or diversity within the data. When the values are near to the center, the sample has low dispersion, whereas high dispersion occurs when they are widely distributed about the center.
Different metrics of dispersion can be employed depending on which is most suited to your dataset and what you want to focus on. The various measurements of dispersion are as follows:
- Standard deviation: This gives a consistent method of determining what is typical, indicating what is unusually large or tiny, and assisting you in understanding the variable’s dispersion from the mean. It represents how near all the values are to the mean.
- Variance: This is comparable to standard deviation, except it indicates how closely or loosely data are distributed around the mean.
- Range: The range represents the difference between the greatest and smallest numbers, indicating the distance between the extremes.
3.Data Summarization in Data Mining: Distribution of a Sample of Data
The distribution of sample data values is determined by its shape, which relates to how data values are dispersed over the sample’s value range. In layman’s words, it indicates that the values are clustered around the average to demonstrate how they are symmetrically placed around it, or that there are more numbers on one side than on the other. Graphical analysis and shape statistics are two methods for investigating the distribution of sample data.
Frequency histograms and tally plots can be used to visually represent the data distribution.
- Histograms: These are similar to bar charts in that a bar shows the frequency of values in the data that correspond to different size classes; however, the bars are drawn without gaps to display the x-axis, which represents a continuous variable.
- Tally plots: A tally plot is a type of frequency distribution graph that may be used to display values in a dataset.
Skewness and kurtosis may be used in shape statistics to determine how central the average is and how clustered the data points are around it.
- Skewness measures how central the average is in the distribution. The skewness of a sample indicates how central the average is to the entire distribution of values.
- Kurtosis is a measure of how pointed a distribution is. The Kurtosis of a sample is a measure of how pointed the distribution is, indicating how clustered the values are at the center.
Determining the shape of your data’s distribution will assist you pick which statistical approach to use when summarizing and analyzing data using data mining.
Conclusion
This post taught you about data summarization in data mining. This article discusses Data Mining, data summarizing, and several approaches to applying Data summarizing in Data Mining.
Oriental Solutions offers a consistent and dependable solution for managing data transfer between a variety of sources and a wide range of desired destinations with a few clicks.



{kind=link}